Enfabrica技術のNVIDIA統合とAIインフラ・バリューチェーンへの影響(投資判断用レポート)
作成日:2026年6月2日/現在時点:2026年6月(GTC 2026は2026年3月開催済み、ロードマップはGTC 2026版を基準)
タグ凡例:【確定】=一次・複数ソースで裏取りした事実/【観測】=アナリスト・ベンダー・報道の見立て(未確定)/【推論】=本レポートの解釈。各主張に確信度(高/中/低)を付す。出典は本文中のURLを参照。
1. エグゼクティブ・サマリー(結論先出し)
投資スタンス(一文):Enfabrica統合は「HBMを減らす技術」ではなく「NVIDIAがシステム販売量と推論TAMを増やすための容量ティア&クラスタ結合技術」であり、cHBM分業シフトと併せても Micron の HBM re-rating テーゼ(core ~80%)は中立〜やや強化。毀損シナリオは限定的だが、Micronの"取り分"はcHBM時代にロジック側(TSMC製造、加えてNVIDIA自社ベースダイ設計は観測段階)へ一部移りうる構造変化を watch する——よって「HBMビット需要は強気、HBM付加価値の独占度はピークアウトに注意」が結論。(確信度:中〜高)
| 層 | 結論(1段落) |
|---|---|
| 構造(10年) | 【推論・高】AIメモリ階層は「HBM(帯域)+ローカルDDR+ファブリック接続CXLプール(容量)」の多層化へ向かう。Enfabrica/EMFASYSはHBMの"下"に安価な容量ティアを足す技術で、HBMの帯域役割を置換しない。ディスアグリゲーションが総HBM需要を構造的に削る力は弱く、推論の経済性改善を通じて総量を下支え〜押し上げる公算が大きい(ただし"総量増"はJevons的な投資仮説であり技術的確定ではない/長コンテキスト推論のHBM容量需要・限界GPU需要を一部削るリスクは残る)。HBM中心は当面続く。 |
| シェア(3–5年) | 【観測・推論/中】NVIDIAはEnfabrica(スケールアウト/メモリファブリック)取り込みで接続レイヤの内製化を一段進め、Broadcom/Astera Labsのスケールアップ・CXL外販に圧力。メモリ側は、cHBM(カスタムHBM)でベースダイがDRAM工程→**ロジックファウンドリ(TSMC N3P)**へ移り(さらにNVIDIA自社ベースダイ設計は観測段階)、HBMの付加価値の一部がメモリ3社からNVIDIA/TSMCへ移転。SK Hynix優位は継続。ただし"設計の主導権"がNVIDIA/TSMC側へ寄るか、カスタム化がメモリ側の粘着性を高めるかは綱引き(NVIDIA自社設計は観測段階)。 |
| 資金フロー(6–18か月) | 【観測/中】カタリストは①HBM4のNVIDIA供給体制(Micronは2026年3月GTCでHBM4 36GB 12Hの量産・Vera Rubin向けを発表済み。残る焦点はSamsung認定可否と3社の割当比率)②HBM契約価格・5年LTA進捗 ③ハイパースケーラーCapEx ④GTC/各社決算でのEnfabrica技術の製品反映言及(次期SuperNIC/BlueField)。Micronは5年HBM契約で可視性が上がり、サイクル長期化テーゼ(Gil Luria:目標$1,000)に追い風。 |
2. Enfabrica技術の実体(リサーチクエスチョンA)
2.1 ACF-S SuperNIC ―― "スイッチを内蔵した超巨大NIC"
【確定・高】Enfabricaのコア製品 ACF-S(Accelerated Compute Fabric – Switch)SuperNIC(開発コード "Millennium")は、3.2 Tbps(≒3.2 Tb/s)級のスループットを持つ単一チップで、本来は別部品である PCIeスイッチ+イーサネット・スイッチ+複数NIC/DMAエンジン+メモリ変換 を1つに統合する。Hot Chips 2024で発表。 (出典:ServeTheHome / MUG25 Enfabrica技術チュートリアル(PDF) / Blocks & Files)
主要スペック(複数ソースで一致/一部は世代・表現差あり):
| 項目 | スペック | 出典・備考 |
|---|---|---|
| スイッチ・スループット | 3.2 Tbps | 全ソース一致【確定・高】 |
| ネットワーク帯域/ポート | 集約スイッチング 3.2 Tbps(確定)。公式表現は「multi-port 800GbE」。初出(Hot Chips 2024)は「32×100GbE+PCIe Gen5 x16×10」=3.2Tbpsと整合。※一部二次報道の「32ポート800/400GbE」は集約3.2Tbpsと桁が合わず、ポート速度/本数の記述はソース間で不一致(要注意) | ServeTheHome/Blocks&Files/BusinessWire【3.2Tbps=確定・高/ポート構成=中】 |
| PCIe | 160レーン(Gen5)/ロードマップでGen6へ | Blocks&Files/MUG25【確定・高】 |
| CXL | CXL 2.0+(144 CXLメモリレーン)/ロードマップでCXL 3.0へ | enfabrica.net・BusinessWire【確定・高】 |
| データムーバ | 40,000 コピーエンジン/data mover(composable DMA/collective offload) | MUG25【確定・中:一次技術資料】 |
| GPU結合 | 単一デバイスで8 GPUを集合的に束ねる(8x スケールアウトRDMA帯域) | enfabrica.net/solution/acf-s【確定・中】 |
【推論・高】ACF-Sの本質は「I/O(ネットワーク+PCIe+メモリ)の集約・オフロード」。GPUサーバ内で散在していたNIC・PCIeスイッチ・ToRスイッチの役割を1チップに集約し、GPU/CPU/ホストメモリ/プールドメモリ間の低レイテンシ経路を作る。これはNVIDIAのConnectX SuperNIC/BlueField DPU/NVLinkと同じ"接続レイヤ"の製品であり、統合先が接続レイヤであることはアーキ上ほぼ自明(後述B章)。
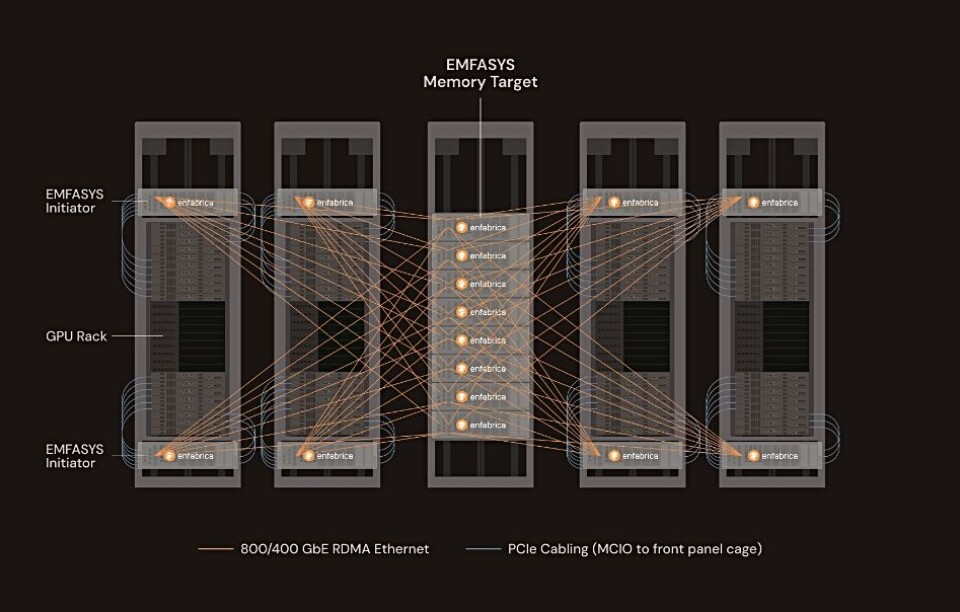

2.2 EMFASYS ―― イーサネット接続のエラスティック・メモリ・ファブリック
【確定・高】EMFASYS(Elastic Memory Fabric System) は、ACF-S SuperNICを中核に、RDMA over Ethernet + CXL DDR5 を統合した「業界初のイーサネットベースAIメモリファブリック・アプライアンス」(2025年7月発表、サンプル出荷中)。 (出典:Enfabrica公式/BusinessWire / enfabrica.net/solution/emfasys / Tom's Hardware)
| 項目 | スペック | 出典 |
|---|---|---|
| プールド容量 | 1ノードあたり最大 18 TB CXL DDR5(将来28 TBへ拡張)/MUG25では4.5〜18 TBレンジ | BusinessWire・MUG25【確定・高】 |
| CXL構成 | 144 CXLレーン/18メモリチャネル、CXL 2.0 | BusinessWire・enfabrica.net【確定・高】 |
| ネットワーク | 400/800 GbE の RDMA over Ethernet バンドル | BusinessWire【確定・高】 |
| RDMA読みレイテンシ | 約6マイクロ秒(GPU HBMとACF-Sターゲットメモリ間)/"マイクロ秒級" | MUG25・BusinessWire【確定・中】 |
| ソフトウェア | InfiniBand Verbsベースのリモートメモリ・スタック(並列転送、複数チャネルへストライピング) | Blocks&Files・MUG25【確定・中】 |
| 容量比 | HBM容量比で 50–100倍の容量ティア | MUG25【観測・中:ベンダー資料】 |
| コスト | CXL DDR5 <15/GB vs HBM3eでKVキャッシュ保持 ~100/GB(≒5–7倍差) | MUG25【観測・中:ベンダー資料】 |
| 効果主張 | 推論のトークンあたりコスト最大50%削減 | BusinessWire・Tom's HW・MUG25【観測・中:ベンダー主張、独立検証は未確認】 |

2.3 何を解決し、何を解決しないか(テーゼの肝)
- 【確定・高】解決するもの=容量バウンドの推論。EMFASYSは「GPU・HBM・ローカルhead-node DDRの消費をオフロード」するHBMの"下"の安価な容量ティアであり、公式に「HBMを置換するのではなく、その消費を肩代わりする補完ティア」と位置づけられる(enfabrica.net・BusinessWire)。対象はエージェント型・バッチ・expert-parallel・高ターン・ロングコンテキスト推論、すなわちKVキャッシュ/長コンテキストの容量問題。CEO Rochan Sankar も「retentive/agentic推論が従来のメモリスケーリングを上回る」と framing(Blocks&Files)。
- 【確定・高】解決しないもの=HBM帯域バウンドの処理。RDMA over Ethernetの~6μsレイテンシは、HBMの数百GB/s〜TB/s・数十nsの帯域/レイテンシ役割を置換できない。学習のプレフィル/行列演算やデコードのホットパスはHBMに残る。EMFASYSは主に推論(一部は学習のactivation/checkpoint/optimizerオフロード)向け。
- 【推論・高】したがって「EMFASYS=HBMキラー」という素朴な解釈は誤り。HBMの帯域需要はそのまま、容量目的の"HBM買い増し"の一部をコモディティDDR5へ逃がすのが本質。これはMicronにとって「HBMが減る」のではなく「HBM以外(コモディティDDR5/モジュール)のTAMが増える」両面を持つ(C章で詳述)。
3. NVIDIA製品への統合:層・タイムライン・戦略意図(リサーチクエスチョンB)
3.1 ディールの実体(再検証)
【確定・高】2025年9月18日、NVIDIAは現金+株式で9億ドル超を投じ、Enfabrica CEO Rochan Sankar と一部従業員を採用、技術をライセンス取得した。買収ではなくacqui-hire+ライセンス。SankarはNVIDIAのネットワーキング・チームへ合流。NVIDIAは2023年のEnfabrica $125M Series B(Atreides Management主導)に既に出資済みで、買収前から資本関係があった。 (出典:CNBC / Network World / Jon Peddie Research)
【確定・中】CNBCは「Enfabrica技術は10万GPU超を結合でき、NVIDIAがGPUクラスタを1台のコンピュータのように統合システムとして提供できるようにする」と報じる。=スケールアウト/クラスタ結合の文脈。
3.2 どの層に入るか(最も確度の高い統合先)
【推論・高(アーキ整合性から)】統合先の最有力は DPU/SuperNIC=接続レイヤ(BlueField系・ConnectX系SuperNIC)、次点でラックスケール・ネットワーキング(Spectrum-X Ethernet/Kyber/Oberonラックのスケールアウト結合)。根拠:
- 【確定】Sankarが合流したのはネットワーキング・チーム(Jon Peddie)。GPUダイ設計でもメモリ設計でもない。
- 【確定】ACF-Sは機能的にConnectX SuperNIC+PCIeスイッチ+メモリ変換の重なり。Jon Peddieは「ACF-SはNVLinkの置換ではなくサーバ間スケーリングの補完として、DGX/Grace/NVLinkトポロジに整合」と記述。
- 【確定】EMFASYSはイーサネット(Spectrum-X系)上のRDMAで動く=NVIDIAのEthernetスケールアウト製品ライン(Spectrum-X、ConnectX/BlueField)と同じ土俵。
【推論・中】よってGPUパッケージ内のHBMには触れない。Enfabricaが効くのは「GPUの外、ラック/クラスタのメモリ&I/Oファブリック」。これがHBMテーゼにとって決定的(=GPU単体HBMは増強トレンドのまま、C章)。
3.3 統合タイムライン(GTC 2026ロードマップ対応)
【確定・高】GTC 2026データセンター・ロードマップの世代構成:
| 時期 | プラットフォーム | GPU/HBM | CPU | DPU | SuperNIC | スイッチ | ラック |
|---|---|---|---|---|---|---|---|
| 2026 | Vera Rubin | Rubin(HBM4) | Vera(88カスタムArm/176スレッド/1.8TB/s NVLink-C2C) | BlueField-4 | ConnectX-9(CX9, ~1600G級/SuperNIC) | NVLink 6 / Spectrum-6 | Oberon |
| 2027(下期) | Rubin Ultra | Rubin Ultra=4 reticle GPU, 1TB HBM4e/パッケージ, 100PF FP4/システムで4.6 PB/s HBM4e・365TB Fast Memory | Vera | BlueField-4 | ConnectX-9(CX9) | NVLink 7(1.5 PB/s) | Kyber(NVL576=8 Oberonラック×72GPU) |
| 2028 | Feynman | Feynman=3Dダイ積層+カスタムHBM(cHBM/C-HBM4E系) | Rosa(新CPU) | BlueField-5 | ConnectX-10 | Spectrum-7(CPO)/NVLink(CPO) | Kyber(copper+CPO) |
(出典:Tom's Hardware GTC2026 / DataCenterDynamics / GTCキーノート・スライド下図)

【注記・確度】スライド上の「115.2 TB/s CX9」はNVL576システム集約のConnectX-9帯域であり、単一SuperNICの仕様ではない(per-NICは~1600G級)。またFeynmanの「1TB超」やNVL576の構成数値はTom's Hardware等の媒体推定を含み、一部は公式確定スペックではない(確度:中)。世代表は「確定の世代構成」と「媒体推定のスペック」が混在する点に留意。

【注記・確度】上図はNVIDIA公式の「Blackwell→Rubin→Feynman」ロードマップ"墓石"スライド(RTX Spark/DGX Stationのクライアント系も併載)。CX8 800G→CX9 1600G→CX10とConnectX世代の per-NIC 速度(CX9=1600G)が読み取れ、§2.1/§3.3の訂正と整合。Grace/Vera/RosaのLPDDR5x/LPDDR6(Spark系)も併記され、§7.1の「推論メモリ階層(SOCAMM/LPDDR)」を裏づける。⚠️年軸(2026〜2030)はRTX Spark/DGX含む広義カデンスで、データセンターGPUの投入時期(Rubin DC 2026・Rubin Ultra 2027・Feynman 2028)とは別軸(直上の世代表が後者)。
【推論・中】Enfabrica技術の最初の製品反映は2028 Feynman世代(BlueField-5/ConnectX-10/Kyberスケールアウト)が本命。理由:①acqui-hireは2025/9、シリコン反映には2–3年 ②Feynman世代はCPO・Kyber・スケールアウト刷新の世代で、ACF-S型のI/O集約・メモリファブリックを盛り込む自然なタイミング。早ければ次期SuperNIC/BlueFieldのファームウェア/機能(EMFASYS的なEthernetメモリターゲット)として2026–2027に部分的に登場しうるが、明示的な公式ロードマップ反映はまだ未確認(watch項目)。確信度:中(タイミングは推論)。
3.4 戦略意図 ―― なぜ買収でなくacqui-hire+ライセンスか
【推論・高】3つの意図が併存:
- 「HBMを減らしたい」より「供給制約を回避してシステム販売量を増やしたい」が主。EMFASYSは「容量目的でGPUを買い増す必要を減らす」が、NVIDIAにとっての果実はHBM逼迫下でも推論ワークロードを捌けるシステムを売り続ける=GPU/システム出荷の天井を上げること。HBMを"敵視"する動機は薄い(NVIDIAはHBMを大量調達する側で、cHBMで主導権も握りにいく=C章)。
- 接続レイヤの内製・防衛。Enfabricaのスケールアウト/メモリファブリックIPを外部(Broadcom/ハイパースケーラー連合)に渡さず取り込み、NVLink/Spectrum-X/ConnectXの優位を補強。
- 規制・スピード。フルM&Aは独禁審査リスク。acqui-hire+ライセンスは人材とIPだけ素早く取り込む手法。【観測】これは2025年に頻発した「擬似買収」(後述)と同型。
【観測・中】Meta/Scale AI型・Google/Windsurf型ディールとの構造比較:いずれも「会社は買わず、創業者+キーパーソン+技術ライセンス/出資で実質的な能力だけを吸収」する2025年の定番スキーム。NVIDIA/Enfabricaも同型で、(a)独禁回避 (b)人材獲得 (c)IPアクセスを同時達成。違いは、Enfabricaが自社製品ロードマップに直結するハード/ネットワーキングIPである点(Scale AI=データ、Windsurf=コーディングAIより、NVIDIAコア事業への垂直統合色が濃い)。
【観測・中】NextPlatform(2026/1)は、ACF-Sを「メモリとホストI/Oを1チップに統合し、独立したNIC・スイッチを不要化」する技術と説明し、EMFASYS×GB200 NVL72で「トークンあたりコスト半減」が可能と整理する一方、**「NVIDIAがより良い推論マシンを作る狙いと、"他社に使わせない"防衛的acqui-hireである可能性は同程度」**と両論を併記する。=統合先・時期は公式には未開示で、本レポート§3.2の統合層特定はアーキ整合性からの推論である点に留意。(出典:NextPlatform: Is Nvidia assembling the parts for its next inference platform)
4. HBM/メモリ需要への影響(リサーチクエスチョンC:テーゼの核心)
4.1 ディスアグリゲーションはHBM需要を減らすか
【推論・高】減らさない。むしろ総需要には中立〜プラス。論点を2つに分けると:
- GPU単体のHBM搭載量:【確定・高】増強トレンド継続。Rubin Ultra=1TB HBM4e/パッケージ、Feynman=3Dダイ積層+カスタムHBMで「GPUパッケージあたり1TB超」。GPU1個に載るHBMは世代ごとに増える。EMFASYSはここに一切触れない。
- データセンター全体のHBM総需要:【推論・高】EMFASYS等のCXLプールは「容量目的のGPU買い増し」を一部代替するが、(a)代替されるのは容量目的の限界的GPUであって帯域目的のGPUではない、(b)推論コストが下がれば推論需要そのものが増える(Jevonsのパラドックス)ためGPU/HBM総量はむしろ増える公算が大きい。ただしこの"総量増"は技術的確定ではなく投資仮説であり、長コンテキスト/agentic推論の容量需要・限界GPU需要が想定超で削られれば反転しうる(→§8)。DataCenterKnowledge「Scaling the Memory Wall」もCXLとHBMは代替でなく補完ティアで、ディスアグリはHBM需要を"増やす"方向と整理(HBM市場
3.9B(2026)→12.4B(2031), Mordor Intelligence)。 (出典:DataCenterKnowledge)
【観測・中】ただしbear要素:CXL/KVキャッシュ・サーバ(Penguin Solutionsが GTC 2026 で発表)やソフト側のKV圧縮(GoogleのTurboQuantは値あたり3.5ビットまで圧縮)が普及すると、HBM容量の限界的増分は鈍りうる。CXL商用採用は**まだ初期(プロトタイプ/初期生産)**で、誇大宣伝先行の側面は残る。
4.2 cHBM(カスタムHBM)による価値連鎖シフト ―― テーゼ上の最重要構造変化
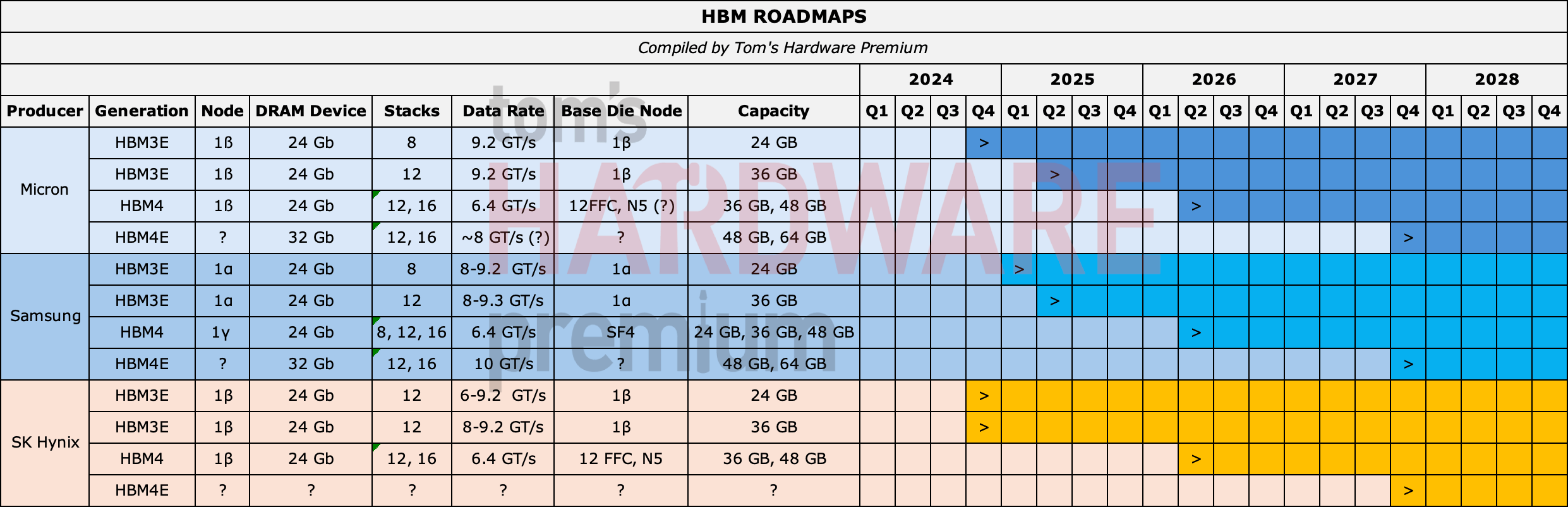
【確定・高】HBMのベースダイ(ロジック層)が、DRAMプロセスからロジックファウンドリ工程へ移る:
- HBM4ベースダイ:TSMC 12FFC+/N5(Micron・SK Hynix)、SamsungはSF4。=すでに先端ロジックノードへ。
- C-HBM4E(カスタムHBM4E):ベースダイを**TSMC N3P(3nmロジック)**で製造し、ロジック/キャッシュ/メモリコントローラ/カスタムD2Dインターフェースをベースダイに統合可能。2.5倍帯域、最大12.8 GT/s、2027市場投入。GUCがHBM4 PHY IPをN3Pでテープアウト(2025/3)。 (出典:Tom's Hardware cHBM/TSMC・GUC / TrendForce C-HBM4E)
【観測・中(サプライチェーン報道。NVIDIA公式発表ではない)】さらに NVIDIA自身がHBMベースダイを設計するとの報道:標準HBM4eを2027上期採用(SK Hynix×TSMC 12nm)した後、カスタムHBM4eを2027下期〜2028に自社設計(SK Hynix×TSMC 3nm)。狙いは「仕様とサプライヤ選定の主導権を握り、TSMC・SK Hynixとの関係を再均衡させ、彼らの交渉力を削ぎ、供給コストを抑える」こと。※これはTrendForce等の供給網報道ベースで、NVIDIAの公式ロードマップ確定事項ではない。後述の「価値連鎖がNVIDIA/TSMCへ移る」結論は、この観測前提に依存する分だけ確度を割り引いて読むべき。 (出典:TrendForce 2027 HBM logic die)
【推論・高】価値連鎖シフトの結論:
- ベースダイのロジック付加価値が メモリメーカー → NVIDIA(設計)+TSMC(製造) へ移る。
- メモリ3社の役割は「DRAMセル+スタッキング(TSV/ハイブリッドボンディング)の供給者」へ純化。=ビット供給は引き続き不可欠だが、"差別化の頭脳"であるベースダイの主導権が薄まる。
- ただし方向は一様ではない【両論併記】:cHBM/カスタム化は(i)ベースダイ主導権の移転=コモディティ化リスクである一方、(ii)Micron自身はカスタムHBMを「差別化機会・顧客との共同R&D深化」と位置づけており、共同設計によるスイッチングコスト上昇・ASP上昇=むしろ再評価(特殊品化)要因にもなり得る。=「メモリ3社の付加価値が一方的に剥落する」と断ずるのは過剰。正味は設計主導権の所在(NVIDIA/TSMC vs メモリ)と、カスタム化がメモリ側の交渉力・粘着性をどれだけ高めるかの綱引きで決まる(Micronにとっては「数量・契約可視性は強気、超過利潤の持続性は綱引き次第」)。
4.3 オフロード先のCXL DDR5需要は誰のTAMか
【推論・高】EMFASYSがプールするのはコモディティCXL DDR5(<$15/GB)。これはMicron/Samsung/SK Hynixの標準DRAM+モジュール事業、およびCXLコントローラ(Astera Labs Leo / Marvell / Microchip 等)のTAM。
- 【推論・中】MicronにとってはHBMの隣に"AIメモリ容量ティア"という新需要が立つ=コモディティDRAM/モジュールの構造的下支え。ただし単価が低く、HBMほどの利益率はない。「ビット需要にプラス、ミックス(利益率)には希薄化圧」。
- 【観測・中】CXLメモリコントローラの本命受益はAstera Labs(Leo)等の専業。NVIDIAがEnfabricaのメモリ変換を内製化したことは、NVIDIAシステム内ではこれら外販コントローラの取り分を侵食しうる(D章)。
5. バリューチェーン・マッピングと競合(リサーチクエスチョンD)
5.1 インパクト一覧表
| プレイヤー | レイヤ | Enfabrica取り込みの影響 | 方向 | 確信度 |
|---|---|---|---|---|
| NVIDIA | GPU/DPU/SuperNIC/NVLink/Spectrum-X/ラック | 接続レイヤ内製化+推論メモリTAM拡大+cHBM主導権(自社設計は観測) | ++ | 高 |
| Micron | HBM(核)/CXL DDR5 | HBMビット需要は強気・5年LTAで可視性↑。cHBMはベースダイ付加価値の一部喪失リスクと、カスタム共同設計による粘着性/ASP↑の両面。CXL DDR5は新規TAM | +(中立寄り+) | 中〜高 |
| SK Hynix | HBM首位 | HBM4/4eでリード継続もベースダイ主導権はNVIDIAへ。数量は強気 | +/注意 | 中 |
| Samsung | HBM/ファウンドリ | HBM4認定が分岐点。ファウンドリ(SF4ベースダイ)で一部取り戻す余地 | ± | 中 |
| TSMC | ロジックファウンドリ | cHBMベースダイ(N3P)の最大受益。HBM価値連鎖に食い込む | ++ | 高 |
| Broadcom | Ethernet scale-up(Tomahawk/Jericho)、Thor SuperNIC | NVIDIAが接続を固める=scale-up Ethernet外販に逆風。ただし非NVIDIA陣営(ハイパースケーラー自製)需要は残存 | −/中立 | 中 |
| Astera Labs | CXL/PCIeリタイマ(Scorpio)、Leo CXLメモリ | NVIDIAシステム内のメモリ変換内製化は逆風。非NVIDIA・CPU側CXLは追い風 | −/± | 中 |
| Marvell | カスタムシリコン/光DSP/CXL | スケールアップ競争激化。光DSPは追い風 | ± | 低〜中 |
| UALink / UEC | スケールアップ/アウト標準連合 | NVIDIAの内製強化は連合の対抗動機を強める(NVIDIAは非加盟色) | ± | 低 |
| Arista / Cisco | データセンタEthernet | AIバックエンドはNVIDIA Spectrum-X/InfiniBandが強い。フロントエンドは残る | −/中立 | 低〜中 |
| Lumentum(LITE)/Coherent(COHR) | 光部品/CPO | Feynman世代のCPO・optical NVLink・スケールアウト拡大は追い風。**NVIDIAが2026/3にCPO向けで各2B=計4B出資(購入コミット+レーザー部品アクセス権)**で関係強化 | +/++ | 中〜高 |
| AAOI | 光トランシーバ | AIバックエンド光需要拡大で追い風だが価格競争 | +/± | 低 |
(競合の技術文脈出典:NextPlatform: Broadcom tries to kill InfiniBand and NVSwitch / [SiliconANGLE: NVIDIA invests 4B in CPO suppliers Lumentum/Coherent(2026/3/2)](https://siliconangle.com/2026/03/02/nvidia-invests-4b-co-packaged-optics-suppliers-lumentum-coherent/)=**本文取得・裏取り済み【確定・中〜高】**(各2B、購入コミット+将来のレーザー部品アクセス権、R&D・米国生産能力向け))
5.2 CXL/メモリプーリングの商用採用度(誇大宣伝 vs 実装実態)
【観測・中】まだ初期段階。CXL 3.0でラックスケールのメモリプーリング/共有が技術的に可能になり、GTC 2026でPenguin SolutionsがCXLベースのMemoryAI KVキャッシュ・サーバを発表したが、広範な商用展開の証跡は乏しく、プロトタイプ/初期生産が中心(DataCenterKnowledge)。Enfabrica EMFASYSも「サンプル出荷中」(2025年央)。具体例としてAstera Labs Leo(CXL 2.0スマートメモリコントローラ、最大2TB/コントローラ・容量+1.5倍)はMicrosoft AzureのM-series VMで"private preview"(2025/11/18)にとどまり本番GAではない(出典:Astera Labs)=大手クラウドが評価着手しつつも採用は初期段階。=テーゼ上、CXL/メモリプーリングの"商用採用率"は最重要watchシグナル(後述)。
5.3 光接続/CPOの方向性
【推論・中→高(裏取りで格上げ)】メモリファブリック(イーサネット上のRDMAでラックを越えてメモリを束ねる)と、Feynman世代のoptical NVLink/Spectrum-X Photonics・Quantum-X Photonics CPOは同じ「スケールアウト帯域の爆発」を駆動する。プールドメモリへの遠隔アクセスが増えるほどラック間の光リンク需要は増える=LITE/COHR等の光部品には構造的追い風。
- 【確定】NVIDIA公式CPOスイッチ:Spectrum-X Photonics(Ethernet, 2026)/Quantum-X Photonics(InfiniBand, 2025)、1.6 Tb/s/port、電力効率3.5倍・レーザー4分の1・帯域密度1.6倍(出典:NVIDIA newsroom)。
- 【確定】NVIDIAは2026/3/2にCPOサプライヤへ各
2B=計4B出資(Lumentum/Coherent、購入コミット+将来のレーザー部品アクセス権、R&D・米国生産能力向け)(出典:SiliconANGLE)。LumentumはOFC 2026で1.6T DR4 OSFP・CPO向け800mW級レーザー等を提示(Lumentum IR)。 - 【推論・中】=メモリファブリックの普及は光接続需要を押し上げる方向で、NVIDIAの$4B出資はその確度を高める(規模・タイミングはなお幅)。
6. 3層フレーム分析(統合)
構造(10年)――AIメモリ・接続アーキはどこへ向かうか
【推論・高】「HBM(帯域・近接)+ローカルDDR+ファブリック接続CXLプール(容量・遠隔)」の多層メモリ階層が標準化する。GPUパッケージは3Dダイ積層+cHBMで帯域・近接容量を増やし続け、その"外側"にEnfabrica型の安価な容量ティアが足される。HBM中心は崩れない。Enfabrica技術はこの大潮流の「容量ティア&ファブリック結合」に位置し、HBMの帯域役割と非競合。メモリの"ディスアグリ化"は進むが、それはHBMの代替ではなくレイヤ追加。
シェア(3–5年)――誰が取り分を増やし、誰が削られるか
【観測・推論/中】
- 増やす:NVIDIA(接続内製化+システムTAM+cHBM主導権〔自社設計は観測〕)、TSMC(cHBMベースダイN3P)、光部品(CPO/スケールアウト)。
- 横ばい〜やや増:Micron/SK Hynix(HBMビット数量は強気だが、ベースダイ付加価値の主導権をNVIDIA/TSMCへ一部移転)。
- 削られる:スケールアップEthernet外販(Broadcom Thor等)とNVIDIAシステム内のCXLメモリ変換外販(Astera Labs Leo)――ただし非NVIDIA陣営(ハイパースケーラー自製・CPU側CXL)需要は残るため致命傷ではない。
- cHBM分業の勝者:**TSMC(ベースダイ製造)**は確度高。NVIDIAの設計主導権奪取は観測段階。メモリ3社は「セル+スタック供給者」へ純化する圧力と、カスタム共同設計で粘着性・ASPを高める余地の綱引き。
資金フロー(6–18か月)――今から株価に効くもの
【観測/中】①HBM4のNVIDIA供給体制(Micronは2026/3 GTCでHBM4 36GB 12H量産・Vera Rubin向けを発表済み→残る焦点はSamsung認定可否・3社の割当比率)②HBM契約価格・5年LTAの進捗 ③ハイパースケーラーCapExの上方修正継続 ④GTC/決算でのEnfabrica技術の製品反映言及(次期SuperNIC/BlueField/Kyber)⑤TrendForce DRAMスポット/契約価格 ⑥CPOサプライヤへのNVIDIA出資の確報。直近はHBM需給タイト&AI CapEx拡大がメモリ株の追い風。 (出典追補:Micron, HBM4 high-volume production for NVIDIA Vera Rubin(2026/3 GTC発表) / Micron FY2Q26 prepared remarks=capex規模・SOCAMM2/DDR/SSD等の推論メモリ階層の構成要素訴求, investors.micron.com)
7. 投資判断(結論)
7.1 Micronテーゼへの影響評価(HBM re-rating仮説)
結論:テーゼは中立〜やや強化(毀損シナリオは限定的)。確信度:中〜高。
【推論・高】強化要因:
- Enfabrica/EMFASYSはHBMの帯域役割を置換しない容量ティア=「EMFASYSがHBMを直接代替する」式の懸念は否定できる(A・C章)。推論経済性の改善でGPU/HBM総量は中立〜増が本線。※「総量が必ず増える」は投資仮説であり技術的確定ではない(容量需要が削られる反証は§8)。
- ディスアグリで増えるCXL DDR5は Micronのコモディティ/モジュールTAMの新規上乗せ。
- Micronの**5年HBM長期契約(LTA)**が需給可視性を上げ、サイクル長期化テーゼの土台。
【推論・中】毀損(注意)要因:
- cHBM分業でベースダイのロジック付加価値がNVIDIA設計+TSMC製造へ移転(2027下期〜2028)。=HBMの超過利潤の"独占度"がピークアウトしうる。Micronの取り分は「数量は維持、単位粗利の持続性に構造的圧力」。
- CXL/KVキャッシュ・サーバ+KV圧縮ソフトの普及がHBM容量の限界的増分を鈍らせるリスク(時期不確実)。
- 供給・価格・利益率の規律(re-ratingの本丸):MicronのFY2026 capexは**$25B超の重い供給局面で、FY2027も建設費増。HBM/DRAMの価格規律・顧客集中(NVIDIA偏重)・契約価格改定・増産後の粗利維持**が崩れれば、需要が強くてもPER拡大は正当化しづらい。「HBM需要」だけ見て「供給過剰=低リスク」とするのは過小評価(→§8で反証を強化)。
【観測・高】Gil Luria(D.A. Davidson)テーゼとの整合:2026/4/28、目標株価**1,000**、**FY2030売上393B・EPS139**、評価は**FY2030 PER10倍×139を3年・年10%で割引**。論拠は「AIインフラ建設が従来より長いメモリサイクルを持続させる(boom-bustの打破)」+「5年HBM契約で可視性向上」。
(出典:indexbox(Gil Luria/D.A. Davidson) / Yahoo Finance / TIKR)
- 【推論・中】本調査結果はLuriaの「サイクル長期化+HBM数量・契約可視性」論拠と整合的(Enfabricaはこれを毀損しない)。ただしLuriaの強気は主に数量×ASP×サイクル長期化に依存し、cHBM分業による"付加価値移転"リスクは織り込みが薄いと見られる。=テーゼの上値(数量)は支持、下振れ感応度(粗利の独占度)はLuria想定よりやや高い。
core ~80%は維持可だが、cHBMシグナル次第で一部を"数量ヘッジ"へ振る余地。 - ⚠️ 表記注意:アナリストは人名 Gil Luria/所属 D.A. Davidson("Thomas Davidson"等の混同は誤り)。
- 【推論・中】「推論メモリ階層」全体での収益ミックス(抜けの補正):HBM/CXLだけでなく、NVIDIA Vera Rubin周辺のSOCAMM2(カスタムLPDRAMモジュール)・LPDDR・SSD/NAND KVキャッシュオフロードまで含めると、Micron全社にはAI由来の多層需要がプラス。Micron公式もHBM・SOCAMM2・DDR・SSDを推論アーキの構成要素として並べて訴求する。ただしこれらはHBMより低ASP/低粗利のため、Micron全社売上には厚い追い風だが、"HBM re-rating"という狭義テーゼの質(ミックス)には希薄化要因でもある=「全社強気」と「HBM単独の超過利潤」は分けて評価すべき。
7.2 NVIDIA(core ~20%)への含意
【推論・高】明確にポジティブ。Enfabrica取り込みは(a)推論システムTAM拡大 (b)接続レイヤの内製・防衛 (c)cHBMでメモリ調達の主導権、の三重取り。Feynman世代(2028)での製品反映が中期カタリスト。core 20%は妥当〜やや増やせる(接続/メモリファブリックの内製は競争堀を深める)。確信度:高。
7.3 光接続銘柄(LITE / COHR / AAOI)への含意
【推論・中】追い風。メモリファブリック+Feynman世代CPO/optical NVLinkはスケールアウト光リンク需要を構造的に押し上げる。NVIDIAの**4B CPO出資(LITE/COHR各2B, 2026/3/2)**が方向性を補強。LITE/COHRはコアの周辺で握る価値あり、AAOIは価格競争でボラ高。確信度:中(方向◎、規模・タイミング△)。
7.4 既存8シグナル・ダッシュボードに追加すべき新シグナル3つ
| # | 新シグナル | なぜ効くか | 取得方法 |
|---|---|---|---|
| 新1 | CXL/メモリプーリングの商用採用率(Penguin/Enfabrica/Astera等の実出荷・本番採用の数) | EMFASYS型容量ティアが普及するほど「容量目的GPU買い増し」が一部代替=HBM限界需要の上下を左右 | GTC/各社IR、ハイパースケーラー採用発表、TrendForce/Omdia |
| 新2 | cHBMベースダイの設計・製造主体(NVIDIA自社設計の進捗、TSMC N3P採用、メモリ各社の関与度) | HBM付加価値がメモリ→NVIDIA/TSMCへ移る速度=Micronの単位粗利の持続性に直結 | TrendForce、TSMC/GUC、NVIDIA調達情報、各社決算 |
| 新3 | NVIDIA SuperNIC/DPU/ラックへのEnfabrica技術反映時期(BlueField-5/ConnectX-10/Kyberでのメモリファブリック実装言及) | 統合が製品化する瞬間が、接続競合(Broadcom/Astera)への逆風と推論TAM拡大の現実化点 | GTCキーノート、NVIDIAネットワーキング発表、Hot Chips |
8. リスク・反証(bear case)――本テーゼが崩れる条件
【推論・各確信度付き】
- 【中】cHBM分業が想定より速く・深く進む:NVIDIA自社設計ベースダイ+TSMC N3Pが2027下期〜2028で主流化し、メモリ3社が「ダム・セル供給者」へ急速にコモディティ化。HBMのASP/粗利プレミアムが縮小→Micron re-ratingの"質"が劣化。Luriaの$1,000は数量で支えても、PER拡大の正当性が揺らぐ。→ watch:cHBMベースダイの設計主体シグナル(新2)。
- 【中〜低】CXL/メモリプーリング+KV圧縮が予想超で普及:EMFASYS型容量ティア+ソフト圧縮(TurboQuant等)で「容量目的のGPU/HBM買い増し」が大きく代替され、HBMビット需要の伸びが鈍化。→ watch:CXL商用採用率(新1)。
- 【中】供給・価格規律の崩れ/増産後の粗利劣化:FY2026 capex $25B超の重い増産局面で、3社増産+AI以外のDRAM需要悪化が重なると価格規律が崩れ従来型boom-bustへ回帰。顧客集中(NVIDIA偏重)下の契約価格改定リスクも。需要が強くても増産後の粗利維持が崩れればre-ratingは正当化されない。Luriaの「サイクル長期化」前提が揺らぐ。→ watch:TrendForceスポット/契約価格、3社capex・割当比率。
- 【低】Enfabrica技術がNVIDIA内で死蔵/遅延:acqui-hire後に製品反映が大幅遅延すれば、接続競合への逆風・推論TAM拡大の現実化が後ろ倒し(NVIDIAテーゼの時間価値毀損、ただしHBMテーゼには軽微)。→ watch:製品反映時期(新3)。
- 【低】Samsung HBM4認定の遅延/不成立:供給寡占が続きMicron/SK Hynixに短期は追い風だが、NVIDIAの"主導権奪取"動機を強め、長期のcHBM分業を加速(1.と連動)。
【推論・高(総括)】最も確度の高いbearは「HBMビット需要の崩壊」ではなく「HBM付加価値の独占度のピークアウト(cHBM分業)+増産後の粗利規律」。=Micronは**"数量・サイクルは強気、超過利潤の持続は要監視"**。テーゼ全体が崩れるより、re-ratingの上限が削られる形のリスクが本命。
テーゼが崩れる最有力シナリオ(単一・要監視):長コンテキスト/agentic推論の主戦場で、EMFASYS型CXL/DDR・SOCAMM/LPDRAM・SSD KVキャッシュオフロード・KV圧縮が実用QoSに到達し、「HBM容量あたりの推論収益」が伸びる前に「トークンあたり必要HBMビット」が大きく低下する展開。この場合HBMは帯域ティアとして残っても、「MicronにPER拡大を与えるほどのHBMビット成長・粗利持続」という中核仮説が崩れる。確信度:中。watch=新1(CXL商用採用率)+新2(cHBM主体)+トークンあたりHBM搭載量の実測トレンド。
9. 出典一覧
主要出典・取得日・信頼度ラベルは 出典は本文中の各URLを参照 に台帳化。取得アセット(図表)は ./ に保存し本文に埋め込み済み(Enfabricaアーキ図×2、EMFASYS実機写真、GTC Rubin Ultraスライド、HBMロードマップ表)。GTC 2026 NVIDIA製品ロードマップ全体図(./gtc2026_full_roadmap.jpg)は agent-browser 経由で取得・埋め込み済み(出典:Tom's Hardware GTC2026)。Codexレビュー後、未取得だった競合・光接続ソース(NextPlatform統合記事/NVIDIA $4B CPO出資/Spectrum-X Photonics/Astera Leo/Lumentum OFC2026)もすべて本文取得で裏取り済み。